
Introduction
The Data Encryption Standard (DES) specifies a FIPS approved cryptographic algorithm. This publication provides a complete description of a mathematical algorithm for encrypting (enciphering) and decrypting (deciphering) binary coded information. Encrypting data converts it to an unintelligible form called cipher. Decrypting cipher converts the data back to its original form called plaintext. The algorithm described in this standard specifies both enciphering and deciphering operations which are based on a binary number called a key.
A key consists of 64 binary digits ("O"s or "1"s) of which 56 bits are randomly generated and used directly by the algorithm. The other 8 bits, which are not used by the algorithm, are used for error detection. The 8 error detecting bits are set to make the parity of each 8-bit byte of the key odd, i.e., there is an odd number of "1"s in each 8-bit byte. Authorized users of encrypted computer data must have the key that was used to encipher the data in order to decrypt it. The unique key chosen for use in a particular application makes the results of encrypting data using the algorithm unique. Selection of a different key causes the cipher that is produced for any given set of inputs to be different. The cryptographic security of the data depends on the security provided for the key used to encipher and decipher the data.
Data can be recovered from cipher only by using exactly the same key used to encipher it. Unauthorized recipients of the cipher who know the algorithm but do not have the correct key cannot derive the original data algorithmically. However, anyone who does have the key and the algorithm can easily decipher the cipher and obtain the original data.
Data can be recovered from cipher only by using exactly the same key used to encipher it. Unauthorized recipients of the cipher who know the algorithm but do not have the correct key cannot derive the original data algorithmically. However, anyone who does have the key and the algorithm can easily decipher the cipher and obtain the original data.
Data that is considered sensitive by the responsible authority, data that has a high value, or data that represents a high value should be cryptographically protected if it is vulnerable to unauthorized disclosure or undetected modification during transmission or while in storage. A risk analysis should be performed under the direction of a responsible authority to determine potential threats. The costs of providing cryptographic protection using this standard as well as alternative methods of providing this protection and their respective costs should be projected. A responsible authority then should make a decision, based on these analyses, whether or not to use cryptographic protection and this standard.
Application
Data encryption (cryptography) is utilized in various applications and environments. The specific utilization of encryption and the implementation of the DES will be based on many factors particular to the computer system and its associated components. In general, cryptography is used to protect data while it is being communicated between two points or while it is stored in a medium vulnerable to physical theft. Communication security provides protection to data by enciphering it at the transmitting point and deciphering it at the receiving point. File security provides protection to data by enciphering it when it is recorded on a storage medium and deciphering it when it is read back from the storage medium. In the first case, the key must be available at the transmitter and receiver simultaneously during communication. In the second case, the key must be maintained and accessible for the duration of the storage period. FIPS 171 provides approved methods for managing the keys used by the algorithm specified in this standard.
Alternative Modes Of Using DES
FIPS PUB 81, DES Modes of Operation, describes four different modes for using the algorithm described in this standard. These four modes are called the Electronic Codebook (ECB) mode, the Cipher Block Chaining (CBC) mode, the Cipher Feedback (CFB) mode, and the Output Feedback (OFB) mode. ECB is a direct application of the DES algorithm to encrypt and decrypt data; CBC is an enhanced mode of ECB which chains together blocks of cipher text; CFB uses previously generated cipher text as input to the DES to generate pseudorandom outputs which are combined with the plaintext to produce cipher, thereby chaining together the resulting cipher; OFB is identical to CFB except that the previous output of the DES is used as input in OFB while the previous cipher is used as input in CFB. OFB does not chain the cipher.
Qualificaions
The cryptographic algorithm specified in this standard transforms a 64-bit binary value into a unique 64-bit binary value based on a 56-bit variable. If the complete 64-bit input is used (i.e., none of the input bits should be predetermined from block to block) and if the 56-bit variable is randomly chosen, no technique other than trying all possible keys using known input and output for the DES will guarantee finding the chosen key. As there are over 70,000,000,000,000,000 (seventy quadrillion) possible keys of 56 bits, the feasibility of deriving a particular key in this way is extremely unlikely in typical threat environments. Moreover, if the key is changed frequently, the risk of this event is greatly diminished. However, users should be aware that it is theoretically possible to derive the key in fewer trials (with a correspondingly lower probability of success depending on the number of keys tried) and should be cautioned to change the key as often as practical. Users must change the key and provide it a high level of protection in order to minimize the potential risks of its unauthorized computation or acquisition. The feasibility of computing the correct key may change with advances in technology.
When correctly implemented and properly used, this standard will provide a high level of cryptographic protection to computer data.
DATA ENCRYPTION ALGORITHM
Introduction
The algorithm is designed to encipher and decipher blocks of data consisting of 64 bits under control of a 64-bit key.** Deciphering must be accomplished by using the same key as for enciphering, but with the schedule of addressing the key bits altered so that the deciphering process is the reverse of the enciphering process. A block to be enciphered is subjected to an initial permutation IP, then to a complex key-dependent computation and finally to a permutation which is the inverse of the initial permutation IP-1. The key-dependent computation can be simply defined in terms of a function f, called the cipher function, and a function KS, called the key schedule. A description of the computation is given first, along with details as to how the algorithm is used for encipherment. Next, the use of the algorithm for decipherment is described. Finally, a definition of the cipher function f is given in terms of primitive functions which are called the selection functions Si and the permutation function P. Si, P and KS of the algorithm are contained in the Appendix.
The following notation is convenient: Given two blocks L and R of bits, LR denotes the block consisting of the bits of L followed by the bits of R. Since concatenation is associative, B1B2...B8, for example, denotes the block consisting of the bits of B1 followed by the bits of B2...followed by the bits of B8.
** Blocks are composed of bits numbered from left to right, i.e., the left most bit of a block is bit one.
** Blocks are composed of bits numbered from left to right, i.e., the left most bit of a block is bit one.

Figure 1. Enciphering computation.
Enciphering
A sketch of the enciphering computation is given in Figure 1.
The 64 bits of the input block to be enciphered are first subjected to the following permutation, called the initial permutation IP:
IP 58 50 42 34 26 18 10 260 52 44 36 28 20 12 462 54 46 38 30 22 14 664 56 48 40 32 24 16 8 57 49 41 33 25 17 9 159 51 43 35 27 19 11 361 53 45 37 29 21 13 563 55 47 39 31 23 15 7That is the permuted input has bit 58 of the input as its first bit, bit 50 as its second bit, and so on with bit 7 as its last bit. The permuted input block is then the input to a complex key-dependent computation described below. The output of that computation, called the preoutput, is then subjected to the following permutation which is the inverse of the initial permutation:
IP-1 40 8 48 16 56 24 64 32
39 7 47 15 55 23 63 31 38 6 46 14 54 22 62 30 37 5 45 13 53 21 61 29 36 4 44 12 52 20 60 28 35 3 43 11 51 19 59 27 34 2 42 10 50 18 58 26 33 1 41 9 49 17 57 25 That is, the output of the algorithm has bit 40 of the preoutput block as its first bit, bit 8 as its second bit, and so on, until bit 25 of the preoutput block is the last bit of the output.
The computation which uses the permuted input block as its input to produce the preoutput block consists, but for a final interchange of blocks, of 16 iterations of a calculation that is described below in terms of the cipher function f which operates on two blocks, one of 32 bits and one of 48 bits, and produces a block of 32 bits.
Let the 64 bits of the input block to an iteration consist of a 32 bit block L followed by a 32 bit block R. Using the notation defined in the introduction, the input block is then LR.
Let K be a block of 48 bits chosen from the 64-bit key. Then the output L'R' of an iteration with input LR is defined by:
(1) L' = R
R' = L(+)f(R,K)where (+) denotes bit-by-bit addition modulo 2.
As remarked before, the input of the first iteration of the calculation is the permuted input block. If L'R' is the output of the 16th iteration then R'L' is the preoutput block. At each iteration a different block K of key bits is chosen from the 64-bit key designated by KEY.
With more notation we can describe the iterations of the computation in more detail. Let KS be a function which takes an integer n in the range from 1 to 16 and a 64-bit block KEY as input and yields as output a 48-bit block Kn which is a permuted selection of bits from KEY. That is
(2) Kn = KS(n,KEY)
with Kn determined by the bits in 48 distinct bit positions of KEY. KS is called the key schedule because the block K used in the n'th iteration of (1) is the block Kn determined by (2).
As before, let the permuted input block be LR. Finally, let L() and R() be respectively L and R and let Ln and Rn be respectively L' and R' of (1) when L and R are respectively Ln-1 and Rn-1 and K is Kn; that is, when n is in the range from 1 to 16,
(3) Ln = Rn-1
Rnn = Ln-1(+)f(Rn-1,Kn)The preoutput block is then R16L16.
The key schedule KS of the algorithm is described in detail in the Appendix. The key schedule produces the 16 Kn which are required for the algorithm.
Deciphering
The permutation IP-1 applied to the preoutput block is the inverse of the initial permutation IP applied to the input. Further, from (1) it follows that:
(4) R = L'
L = R' (+) f(L',K)Consequently, to decipher it is only necessary to apply the very same algorithm to an enciphered message block, taking care that at each iteration of the computation the same block of key bits K is used during decipherment as was used during the encipherment of the block. Using the notation of the previous section, this can be expressed by the equations:
(5) Rn-1 = Ln
Ln-1 = Rn (+) f(Ln,Kn) where now R16L16 is the permuted input block for the deciphering calculation and L() and R() is the preoutput block. That is, for the decipherment calculation with R16L16 as the permuted input, K16 is used in the first iteration, K15 in the second, and so on, with K1 used in the 16th iteration.
The Cipher Function f
A sketch of the calculation of f(R,K) is given in Figure 2.

Figure 2. Calculation of f(R,K).
Let E denote a function which takes a block of 32 bits as input and yields a block of 48 bits as output. Let E be such that the 48 bits of its output, written as 8 blocks of 6 bits each, are obtained by selecting the bits in its inputs in order according to the following table:
E BIT-SELECTION TABLE 32 1 2 3 4 5
4 5 6 7 8 9 8 9 10 11 12 13 12 13 14 15 16 17 16 17 18 19 20 21 20 21 22 23 24 25 24 25 26 27 28 29 28 29 30 31 32 1 Thus the first three bits of E(R) are the bits in positions 32, 1 and 2 of R while the last 2 bits of E(R) are the bits in positions 32 and 1.
Each of the unique selection functions S1,S2,...,S8, takes a 6-bit block as input and yields a 4-bit block as output and is illustrated by using a table containing the recommended S1:
S1 Column Number
RowNo. 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 14 4 13 1 2 15 11 8 3 10 6 12 5 9 0 7
1 0 15 7 4 14 2 13 1 10 6 12 11 9 5 3 82 4 1 14 8 13 6 2 11 15 12 9 7 3 10 5 03 15 12 8 2 4 9 1 7 5 11 3 14 10 0 6 13 If S1 is the function defined in this table and B is a block of 6 bits, then S1(B)is determined as follows: The first and last bits of B represent in base 2 a number in the range 0 to 3. Let that number be i. The middle 4 bits of B represent in base 2 a number in the range 0 to 15. Let that number be j. Look up in the table the number in the i'th row and j'th column. It is a number in the range 0 to 15 and is uniquely represented by a 4 bit block. That block is the output S1(B) of S1 for the input B. For example, for input 011011 the row is 01, that is row 1, and the column is determined by 1101, that is column 13. In row 1 column 13 appears 5 so that the output is 0101. Selection functions S1,S2,...,S8 of the algorithm appear in the Appendix.
The permutation function P yields a 32-bit output from a 32-bit input by permuting the bits of the input block. Such a function is defined by the following table:
P 16 7 20 21 29 12 28 17 1 15 23 26 5 18 31 10 2 8 24 14 32 27 3 9 19 13 30 6 22 11 4 25The output P(L) for the function P defined by this table is obtained from the input L by taking the 16th bit of L as the first bit of P(L), the 7th bit as the second bit of P(L), and so on until the 25th bit of L is taken as the 32nd bit of P(L).
Now let S1,...,S8 be eight distinct selection functions, let P be the permutation function and let E be the function defined above.
To define f(R,K) we first define B1,...,B8 to be blocks of 6 bits each for which
(6) B1B2...B8 = K(+)E(R)
The block f(R,K) is then defined to be
(7)
P(S1(B1)S2(B2)...S8(B8))Thus K(+)E(R) is first divided into the 8 blocks as indicated in (6). Then each Bi is taken as an input to Si and the 8 blocks (S1(B1)S2(B2)...S8(B8) of 4 bits each are consolidated into a single block of 32 bits which forms the input to P. The output (7) is then the output of the function f for the inputs R and K.
PRIMITIVE FUNCTIONS FOR THE DATA ENCRYPTION ALGORITHM
The choice of the primitive functions KS, S1,...,S8 and P is critical to the strength of an encipherment resulting from the algorithm. Specified below is the recommended set of functions, describing S1,...,S8 and P in the same way they are described in the algorithm. For the interpretation of the tables describing these functions, see the discussion in the body of the algorithm.
The primitive functions S1,...,S8 are:
S1
14 4 13 1 2 15 11 8 3 10 6 12 5 9 0 7 O 15 7 4 14 2 13 1 10 6 12 11 9 5 3 8 4 1 14 8 13 6 2 11 15 12 9 7 3 10 5 0 15 12 8 2 4 9 1 7 5 11 3 14 10 O 6 13 S2
15 1 8 14 6 11 3 4 9 7 2 13 12 O 5 10 3 13 4 7 15 2 8 14 12 0 1 10 6 9 11 5 0 14 7 11 10 4 13 1 5 8 12 6 9 3 2 15 13 8 10 1 3 15 4 2 11 6 7 12 0 5 14 9 S3 10 0 9 14 6 3 15 5 1 13 12 7 11 4 2 8 13 7 O 9 3 4 6 10 2 8 5 14 12 11 15 1 13 6 4 9 8 15 3 0 11 1 2 12 5 10 14 7 1 10 13 0 6 9 8 7 4 15 14 3 11 5 2 12 S4
7 13 14 3 0 6 9 10 1 2 8 5 11 12 4 15 13 8 11 5 6 15 O 3 4 7 2 12 1 10 14 9 10 6 9 0 12 11 7 13 15 1 3 14 5 2 8 4 3 15 O 6 10 1 13 8 9 4 5 11 12 7 2 14 S5
2 12 4 1 7 10 11 6 8 5 3 15 13 O 14 9 14 11 2 12 4 7 13 1 5 0 15 10 3 9 8 6 4 2 1 11 10 13 7 8 15 9 12 5 6 3 O 14 11 8 12 7 1 14 2 13 6 15 O 9 10 4 5 3 S6
12 1 10 15 9 2 6 8 O 13 3 4 14 7 5 11 10 15 4 2 7 12 9 5 6 1 13 14 O 11 3 8 9 14 15 5 2 8 12 3 7 0 4 10 1 13 11 6 4 3 2 12 9 5 15 10 11 14 1 7 6 0 8 13 S7
4 11 2 14 15 0 8 13 3 12 9 7 5 10 6 1 13 0 11 7 4 9 1 10 14 3 5 12 2 15 8 6 1 4 11 13 12 3 7 14 10 15 6 8 0 5 9 2 6 11 13 8 1 4 10 7 9 5 0 15 14 2 3 12 S8
13 2 8 4 6 15 11 1 10 9 3 14 5 0 12 7 1 15 13 8 10 3 7 4 12 5 6 11 0 14 9 2 7 11 4 1 9 12 14 2 0 6 10 13 15 3 5 8 2 1 14 7 4 10 8 13 15 12 9 0 3 5 6 11 The primitive function P is:
16 7 20 21 29 12 28 17 1 15 23 26 5 18 31 10 2 8 24 14 32 27 3 9 19 13 30 6 22 11 4 25 Recall that Kn, for 1<= n <= 16, is the block of 48 bits in (2) of the algorithm. Hence, to describe KS, it is sufficient to describe the calculation of Kn from
KEY for n = 1, 2,..., 16. That calculation is illustrated in Figure 3. To complete the definition of KS it is therefore sufficient to describe the two permuted choices, as well as the schedule of left shifts. One bit in each 8-bit byte of the KEY may be utilized for error detection in key generation, distribution and storage. Bits 8, 16,..., 64 are for use in assuring that each byte is of odd parity.
Permuted choice 1 is determined by the following table:
PC-1 57 49 41 33 25 17 9 1 58 50 42 34 26 18 10 2 59 51 43 35 27 19 11 3 60 52 44 36 63 55 47 39 31 23 15 7 62 54 46 38 30 22 14 6 61 53 45 37 29 21 13 5 28 20 12 4 The table has been divided into two parts, with the first part determining how the bits of C() are chosen, and the second part determining how the bits of D() are chosen. The bits of KEY are numbered 1 through 64. The bits of C() are respectively bits 57, 49, 41,..., 44 and 36 of KEY, with the bits of D() being bits 63, 55, 47,..., 12 and 4 of KEY.
With C() and D() defined, we now define how the blocks Cn and Dn are obtained from the blocks Cn-1 and Dn-1, respectively, for n = 1, 2,..., 16. That is accomplished by adhering to the following schedule of left shifts of the individual blocks:
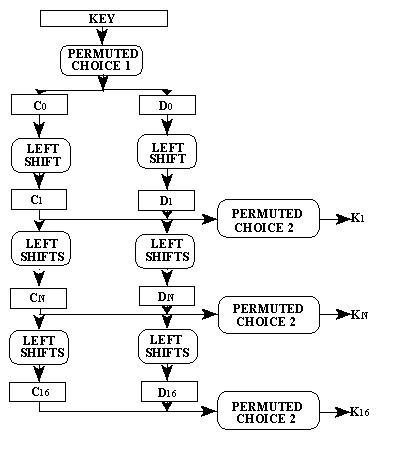
Figure 3. Key schedule calculation.
Iteration Number of Number Left Shifts 1 1 2 1 3 2 4 2 5 2 6 2 7 2 8 2 9 1 10 2 11 2 12 2 13 2 14 2 15 2 16 1 For example, C3 and D3 are obtained from C2 and D2, respectively, by two left shifts, and C16 and D16 are obtained from C15 and D15, respectively, by one left shif. In all cases, by a single left shift is meant a rotation of the bits one place to the left, so that after one left shift the bits in the 28 positions are the bits that were previously in positions 2, 3,..., 28, 1.
Permuted choice 2 is determined by the following table:
PC-2 14 17 11 24 1 5 3 28 15 6 21 10 23 19 12 4 26 8 16 7 27 20 13 2 41 52 31 37 47 55 30 40 51 45 33 48 44 49 39 56 34 53 46 42 50 36 29 32Therefore, the first bit of Kn is the 14th bit of CnDn, the second bit the 17th, and so on with the 47th bit the 29th, and the 48th bit the 32nd.
Simplified DES
Simplified DES (S-DES) has similar properties and structure to DES with much smaller parameters (See following S-DES scheme).

Following is the key generation process:

Where P10 is a permutation with table:
P10 | |||||||||
3 | 5 | 2 | 7 | 4 | 10 | 1 | 9 | 8 | 6 |
LS-1 is a circular left shift of 1 bit position, and LS-2 is a circular left shift of 2 bit positions.
P8 is another permutation with the following rule:
P8 | |||||||
6 | 3 | 7 | 4 | 8 | 5 | 10 | 9 |
Encryption:

IP is the initial permutation and IP-1 is its inverse.
IP | |||||||
2 | 6 | 3 | 1 | 4 | 8 | 5 | 7 |
IP-1 | |||||||
4 | 1 | 3 | 5 | 7 | 2 | 8 | 6 |
Function fK consists of a combination of permutation and substitution functions. fK(L, R) = (L Å F(R, SK), R) where SK is a subkey (i.e. K1 or K2).
E/P is an expansion permutation, with the following rules:
E/P | |||||||
4 | 1 | 2 | 3 | 2 | 3 | 4 | 1 |
S0 and S1 are to S-boxes operates according to the following tables:
S0:
1 | 0 | 3 | 2 |
3 | 2 | 1 | 0 |
0 | 2 | 1 | 3 |
3 | 1 | 3 | 2 |
S1:
0 | 1 | 2 | 3 |
2 | 0 | 1 | 3 |
3 | 0 | 1 | 0 |
2 | 1 | 0 | 3 |
And P4 would be another permutation.
P4 | |||
2 | 3 | 4 | 1 |